Как «вытащить» текст из PDF-файла или фотографии. Online OCR
Извлекайте текст в три клика и бесплатно.
У вас есть сфотографированный документ или PDF-файл, и вам нужен оттуда текст? Не перенабирайте его, воспользуйтесь онлайн-сервисом. Рассказываем, как им пользоваться.
Бесплатный сервис Online OCR для распознавания текста в отсканированных PDF-документах (в том числе многостраничных файлов), факсах и фотографиях (jpg, tiff, bmp, gif). На выходе пользователь получает текст в форматах Word, Excel и Text. На сервисе сказано, что выходные документы имеют исходную структуру — таблицы, колонки и графические объекты.
Без регистрации бесплатно можно распознать 15 страниц в час. Регистрация дает доступ к дополнительным возможностям сервиса: конвертирование больших файлов, ZIP архивов и многостраничных PDF, выбор языков распознавания, больший выбор выходных форматов.
Открывайте OnlineOCR.net. Извлекать и конвертировать текст просто как в гостевом режиме, так и после регистрации. Схема действий идентичная.
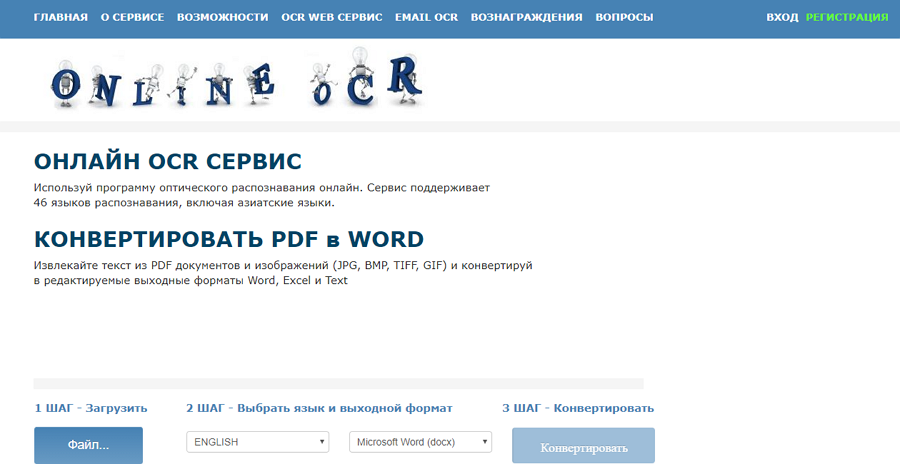
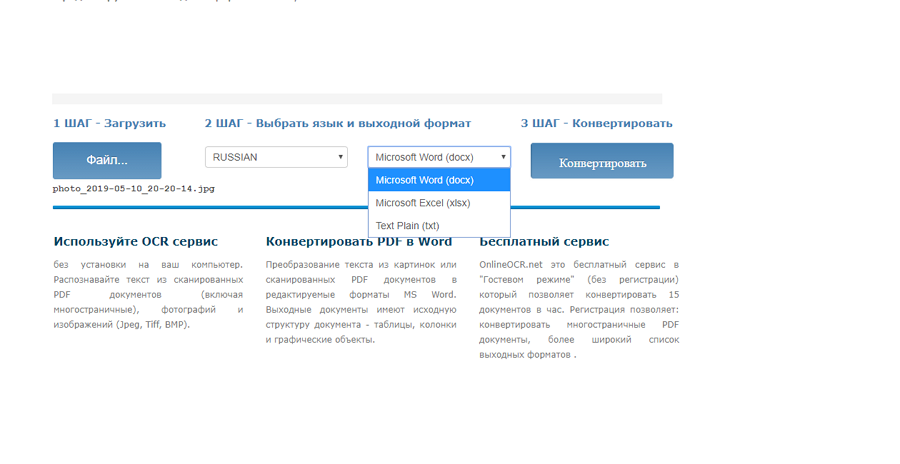
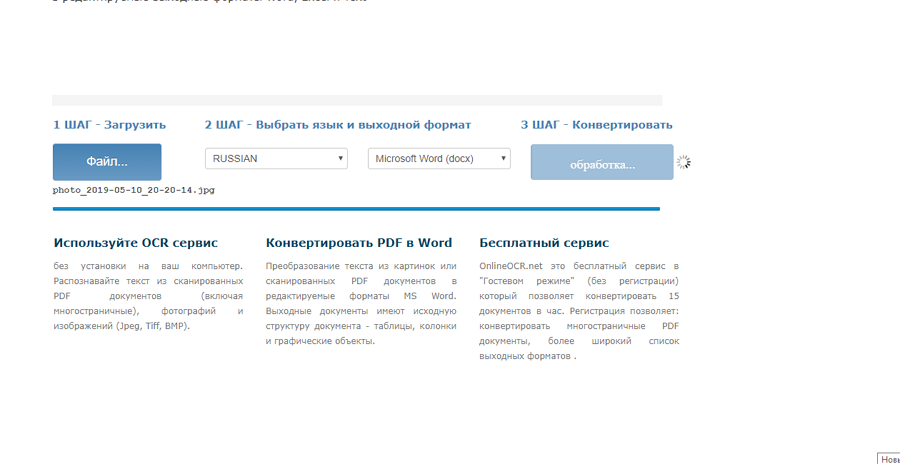
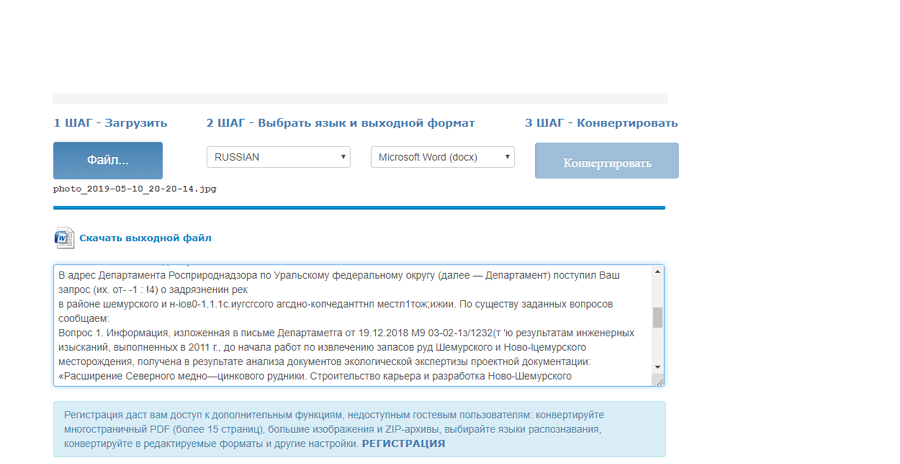
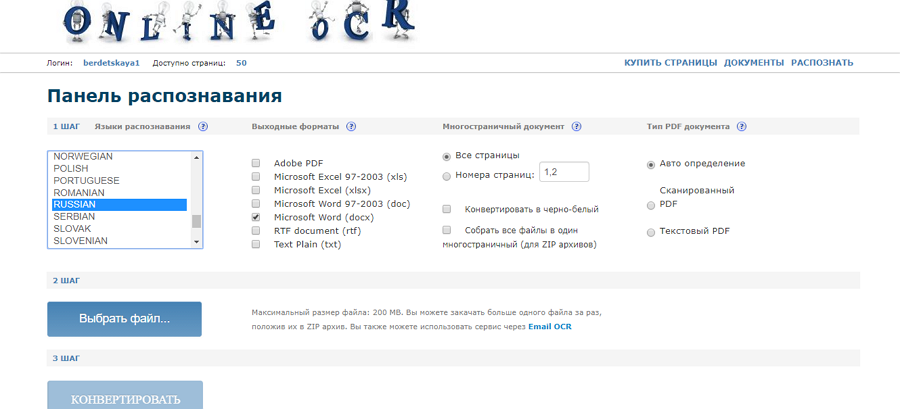
Нажимайте «Файл» для загрузки документа. Выбирайте язык и выходной формат. Кликайте на «Конвертировать». Скачивайте готовый файл.
На фото ниже — пошаговая инструкция для работы на сервисе без регистрации.
После регистрации сначала выбирайте язык и выходной формат, после загружайте файл и нажимайте «Конвертировать».
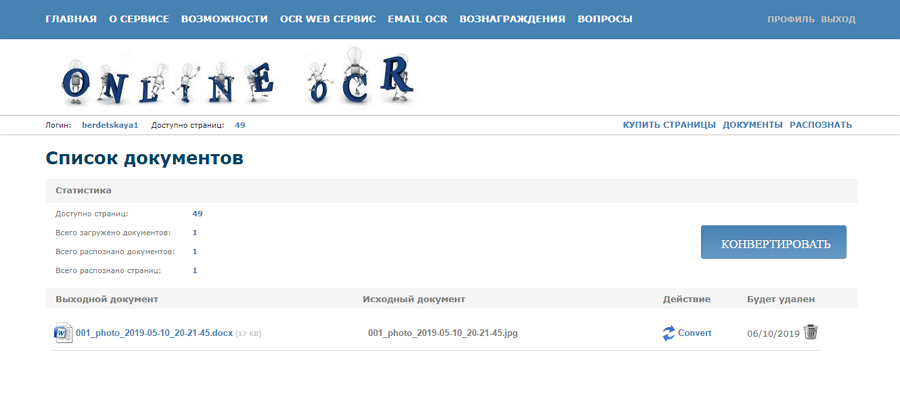
У сервиса есть минус: если исходный файл не очень хорошего качества, то некоторые слова или фразы он не распознает и выдаст их набором букв. Просмотрите документ и в случае необходимости подкорректируйте.
Подводя итоги:
Возможно, вам пригодится:

Как опубликовать на сайте PDF-файл. Google Диск

Как быстро извлечь картинки из PDF. PDFCandy

Как залить гиф-анимацию в сторис в Инстаграм*. 123apps

