Как очистить таблицу с данными для дальнейшей работы
Найти чистые и готовые к обработке датасеты получается не всегда. Поэтому представляем пять базовых шагов по очистке данных, которые помогут выйти победителями из схватки с очередной запутанной таблицей.
Шаг 1. Определяем, что хотим узнать
Поймите, что конкретно вам надо найти в данных. Для взаимодействия с любой таблицей нужна гипотеза. Часто ее удобно формулировать в виде вопроса. Так вы ступаете на тропу сторителлинга. В каком возрасте россияне женятся и разводятся? Как меняется погода в Петербурге в течении года? Какие изменения произошли с продуктовой корзиной с Нового года?
Уже с существующим вопросом-гипотезой стоит приходить в датасет. Вопрос, как бы неожиданно это ни звучало, должен быть конкретным и измеряемым.
Какие бывают вопросы?
Количественные: сколько детей рождается в российских семьях?
Качественные: как этот показатель меняется по регионам? Как было в начале нулевых? А если сравнить с европейской демографической ситуацией — это много или мало? А если сравнить со странами Азии?
Шаг 2. Убираем исходное форматирование
Очень вероятно, что с таблицей уже работали до вас и установили определенные настройки: выделили ячейки цветом, сгруппировали их. Эти настройки могут мешать.
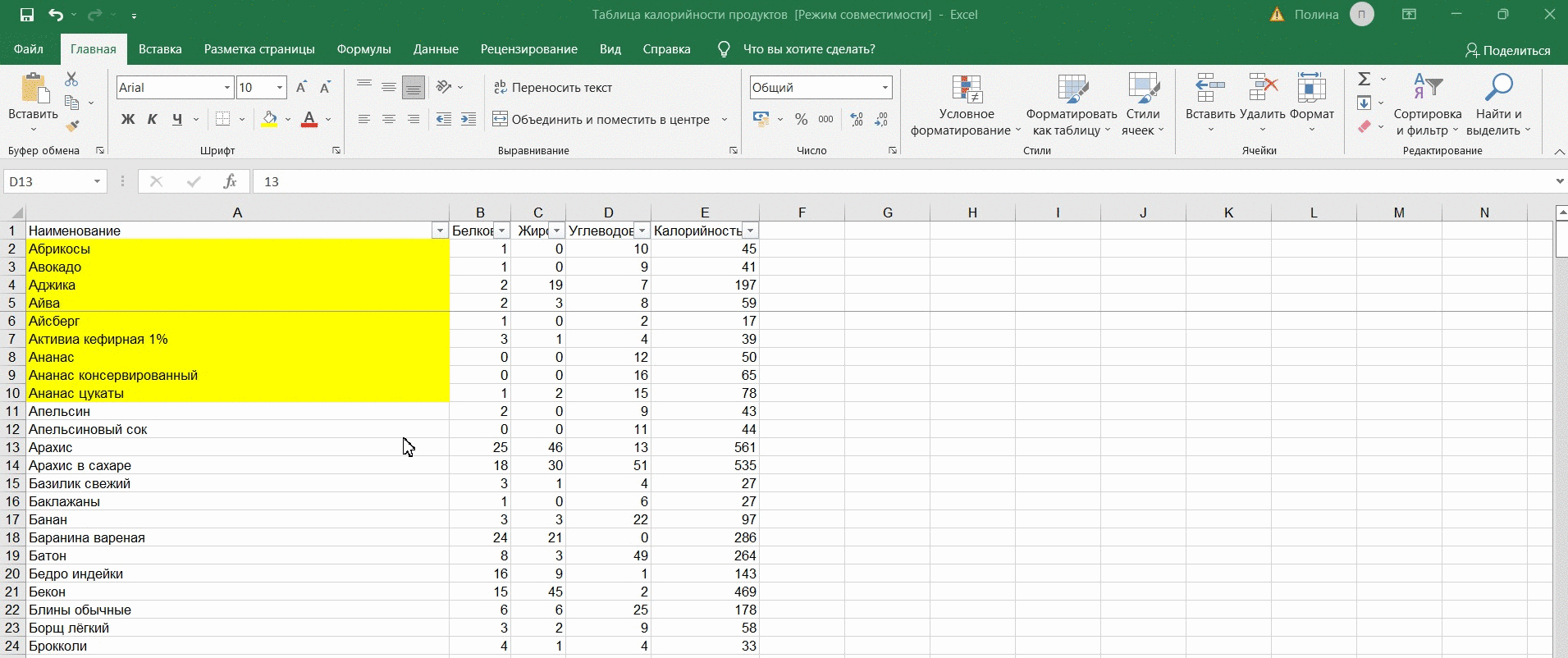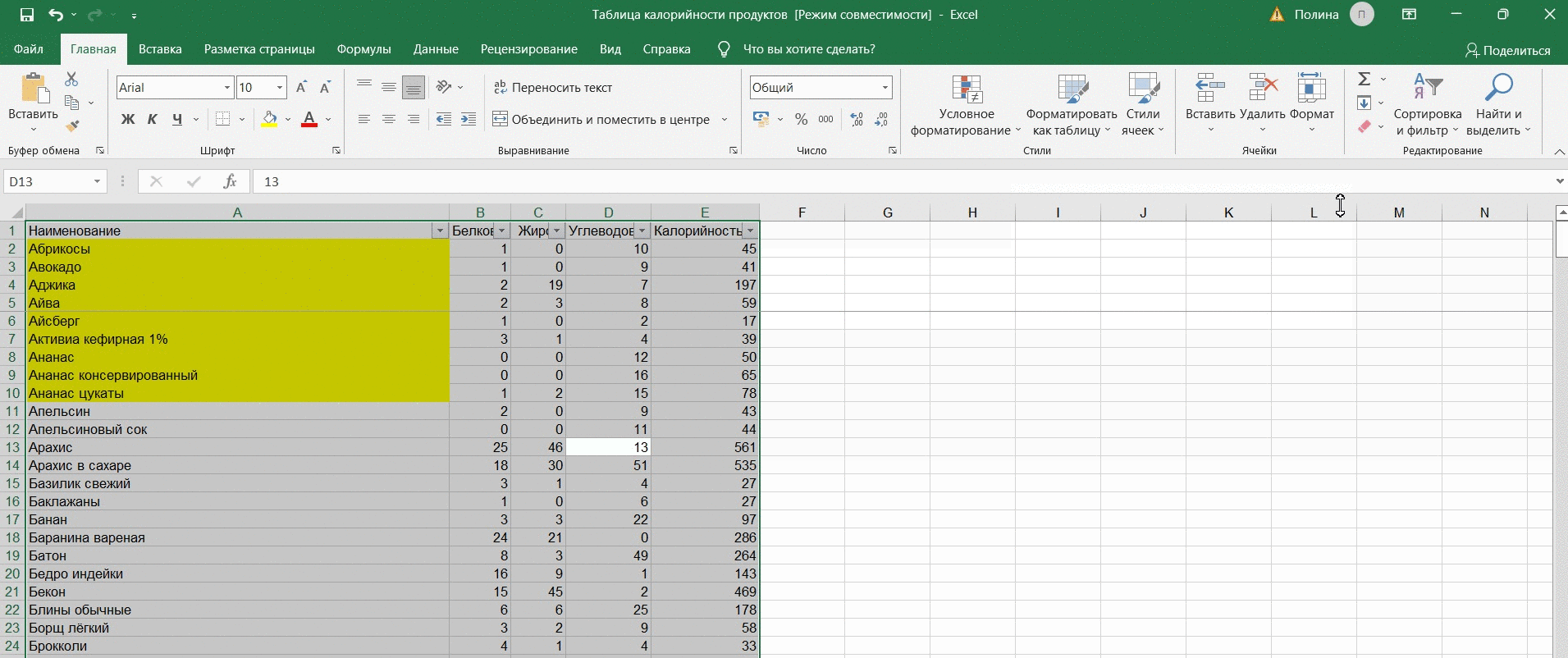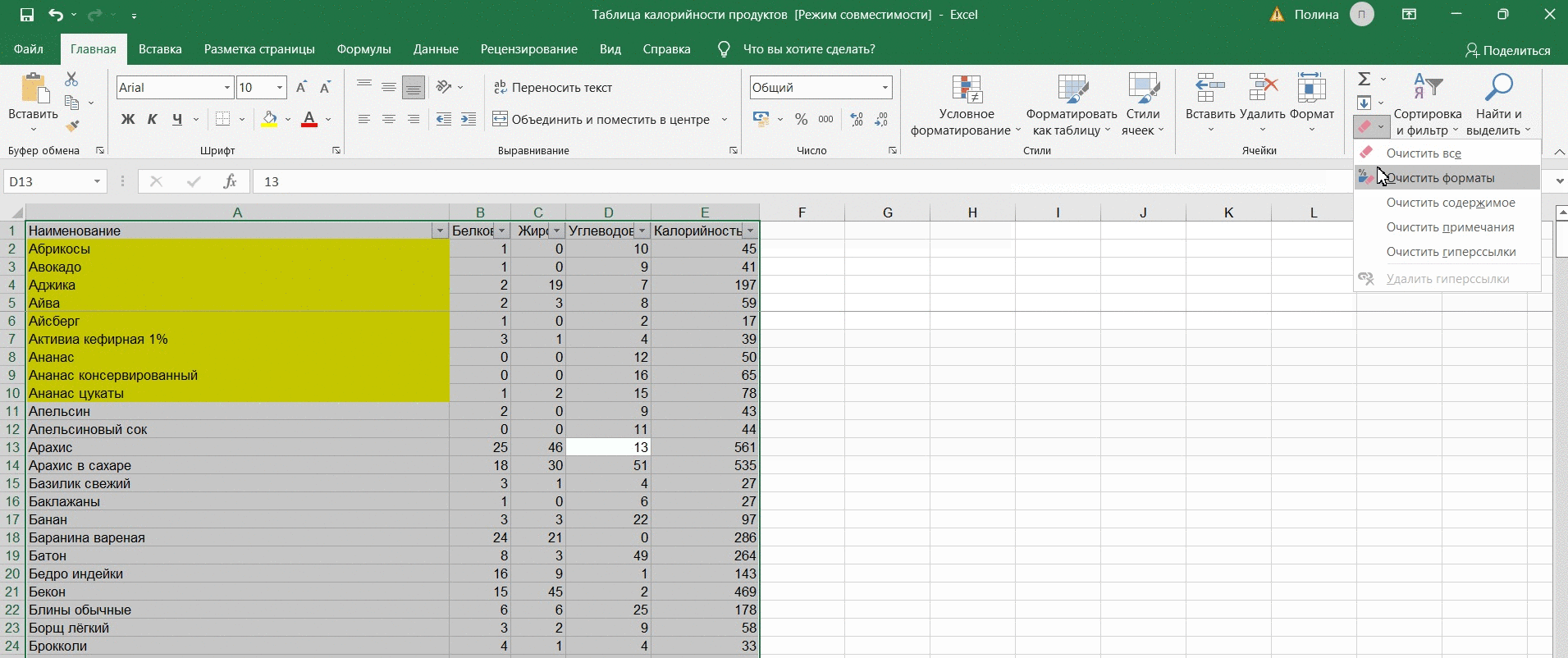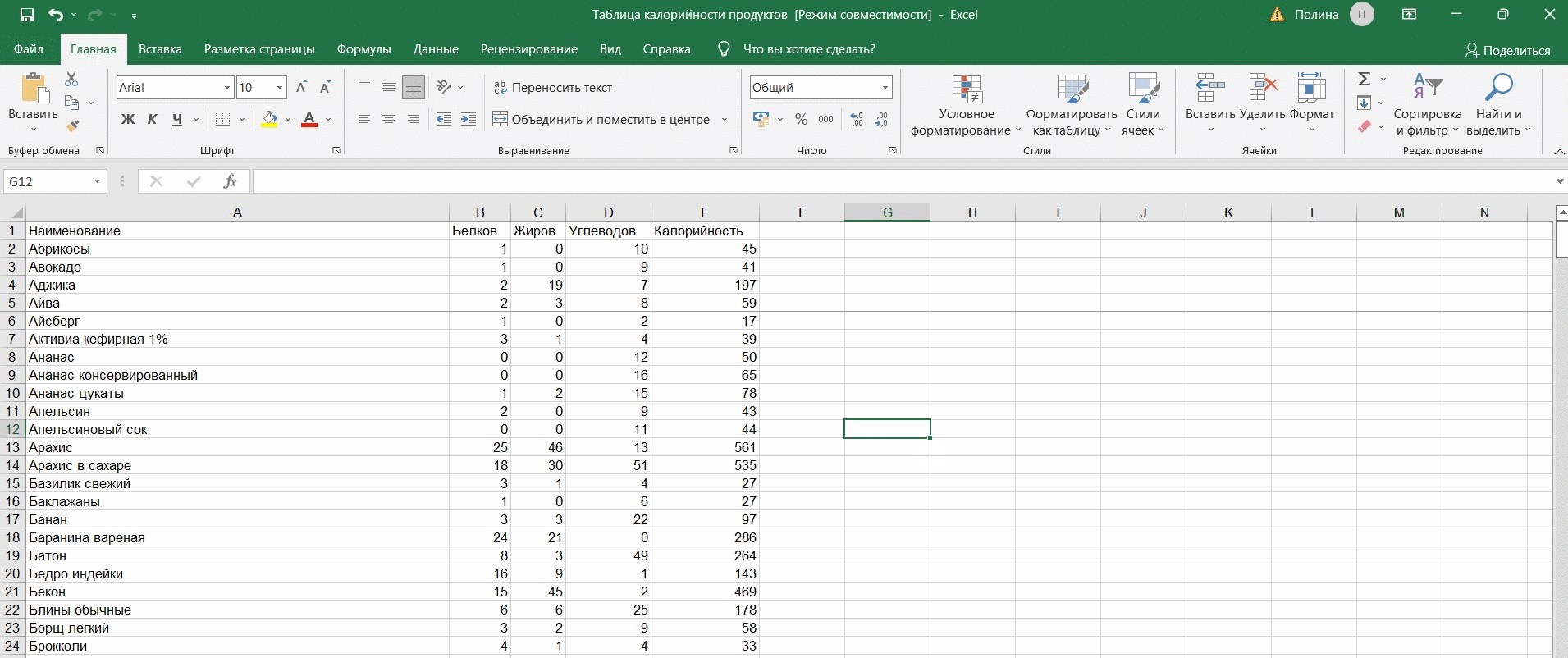
Поэтому выделяем всю таблицу, переходим в «Формат» и выбираем «Очистить форматирование».
Часто после этой процедуры может измениться числовой формат. Это связано с тем, что в России десятичный разделитель — запятая, а в англоязычных странах — точка.
Шаг 3. Чиним числовой формат
Для этого используем функцию «Правка» — «Найти и заменить». Выделяем столбец, применяем функции, указываем, что меняем и на что. Нажимаем «Заменить все».

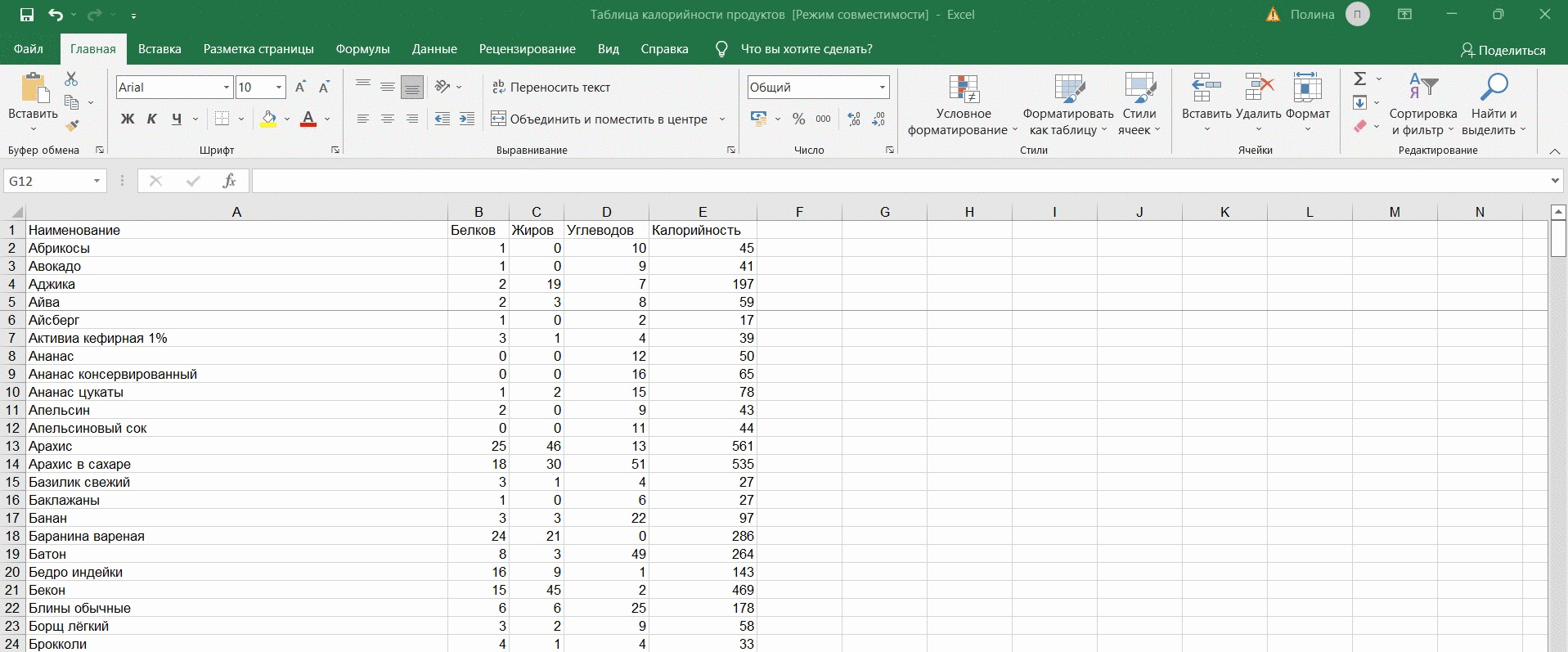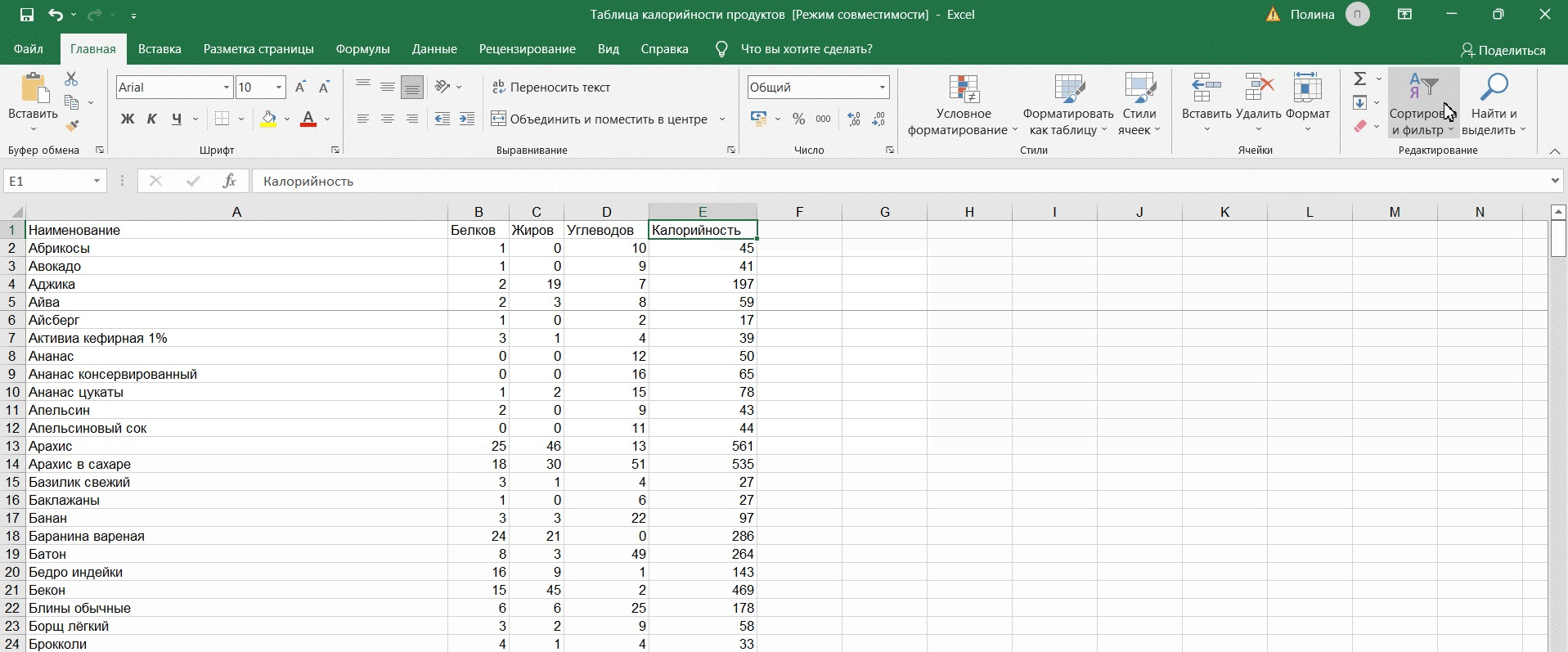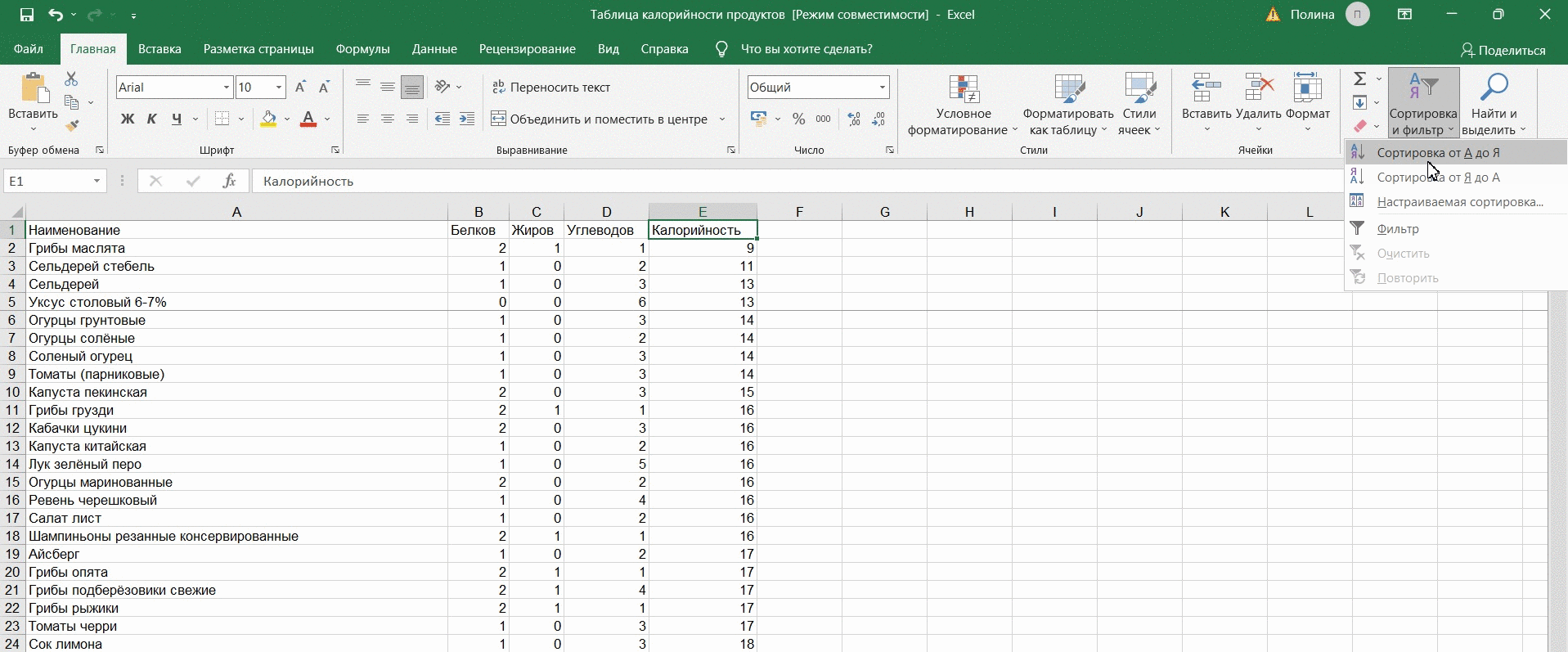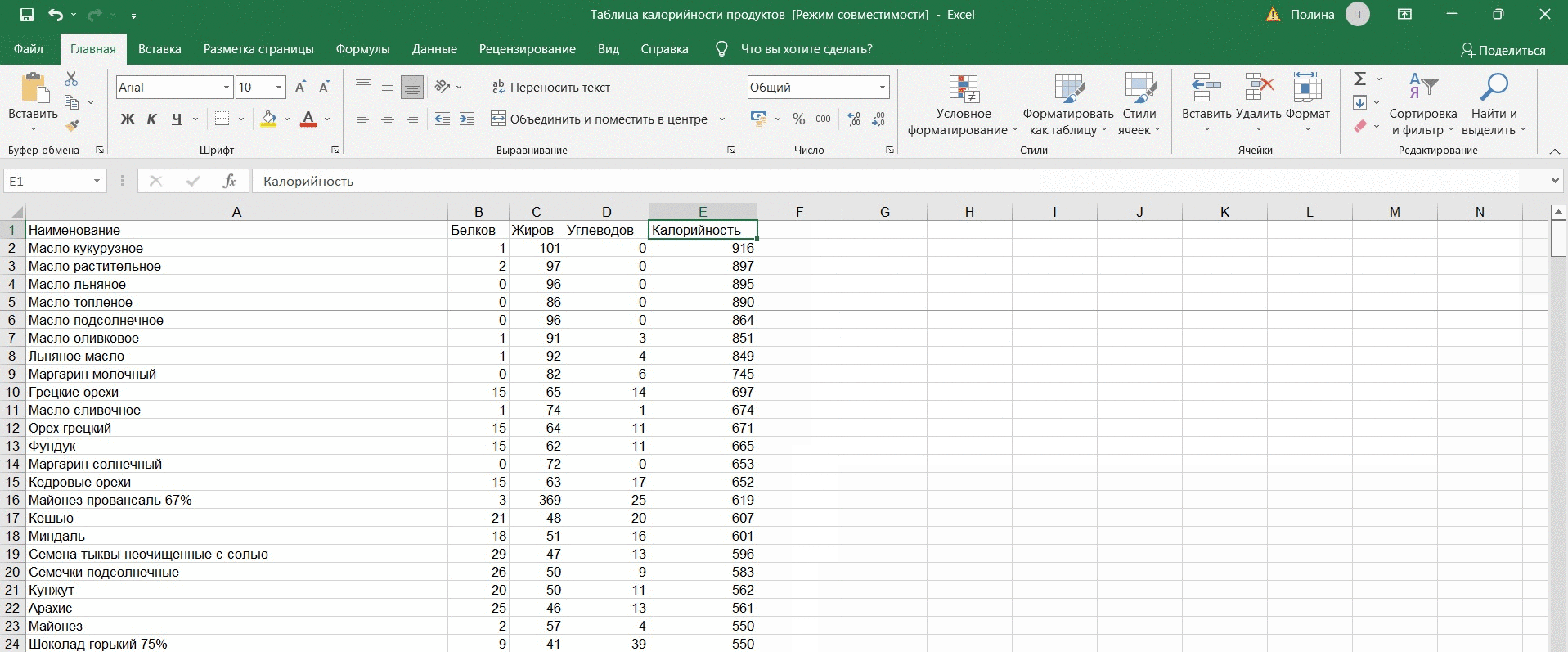
Шаг 4. Сортируем данные (если нужно)
Чтобы лучше увидеть динамику данных, нужно их отсортировать по значению. Для этого используем фильтр «от А до Я», если нас интересует возрастание, и «от Я до А», если хотим увидеть данные, отсортированные от большего к меньшему.
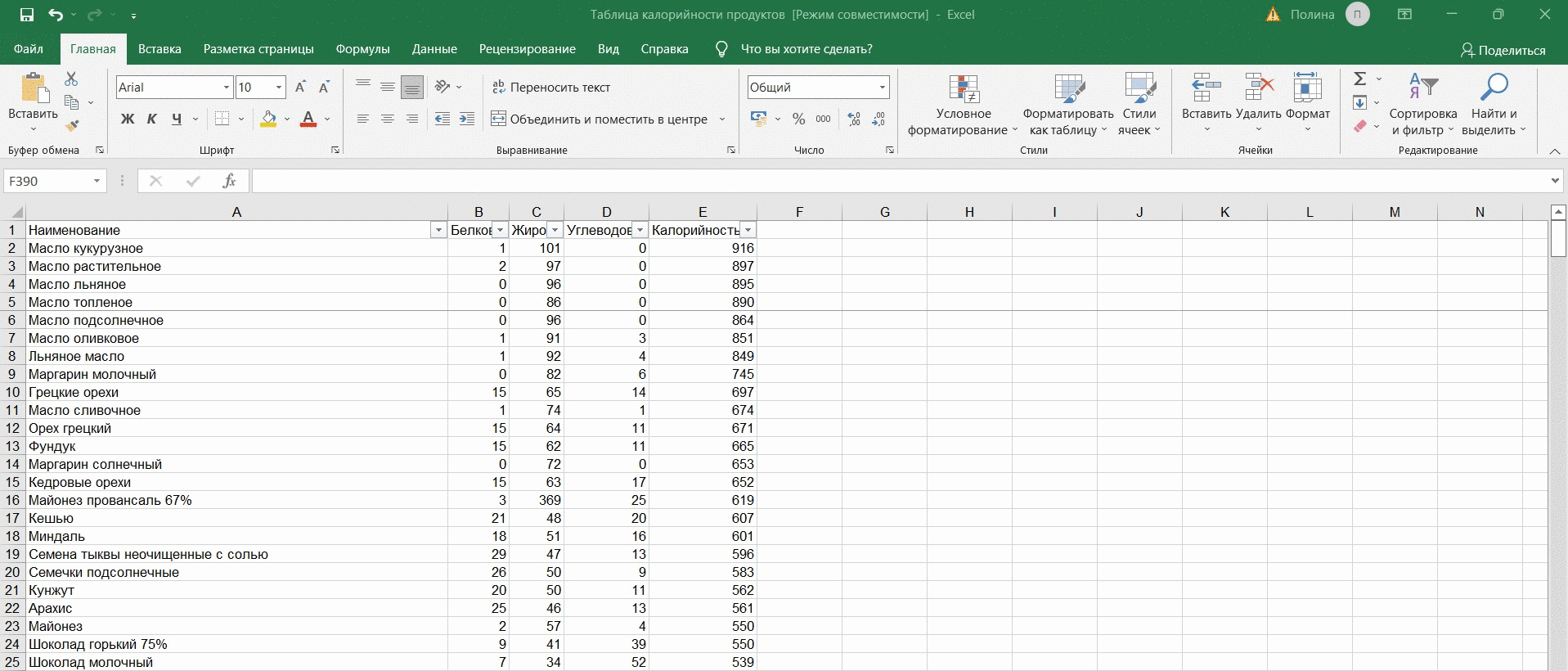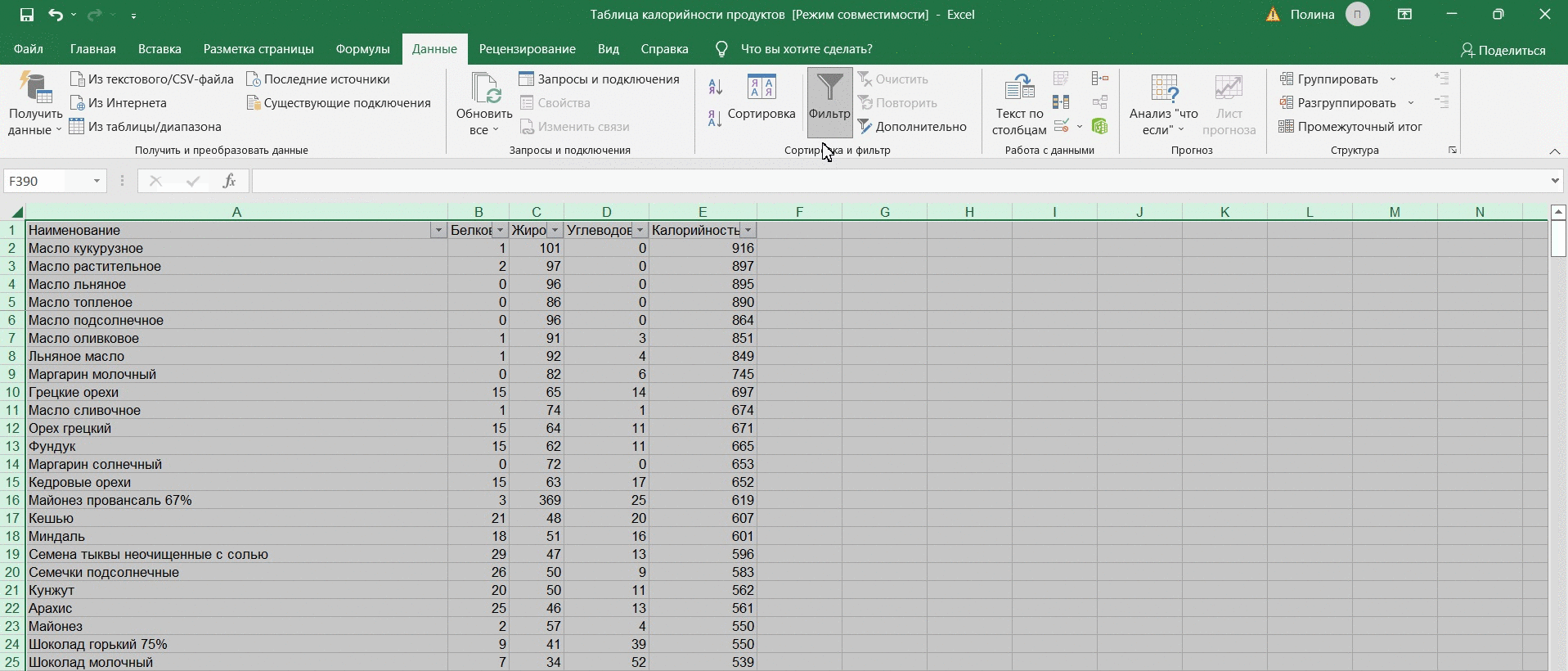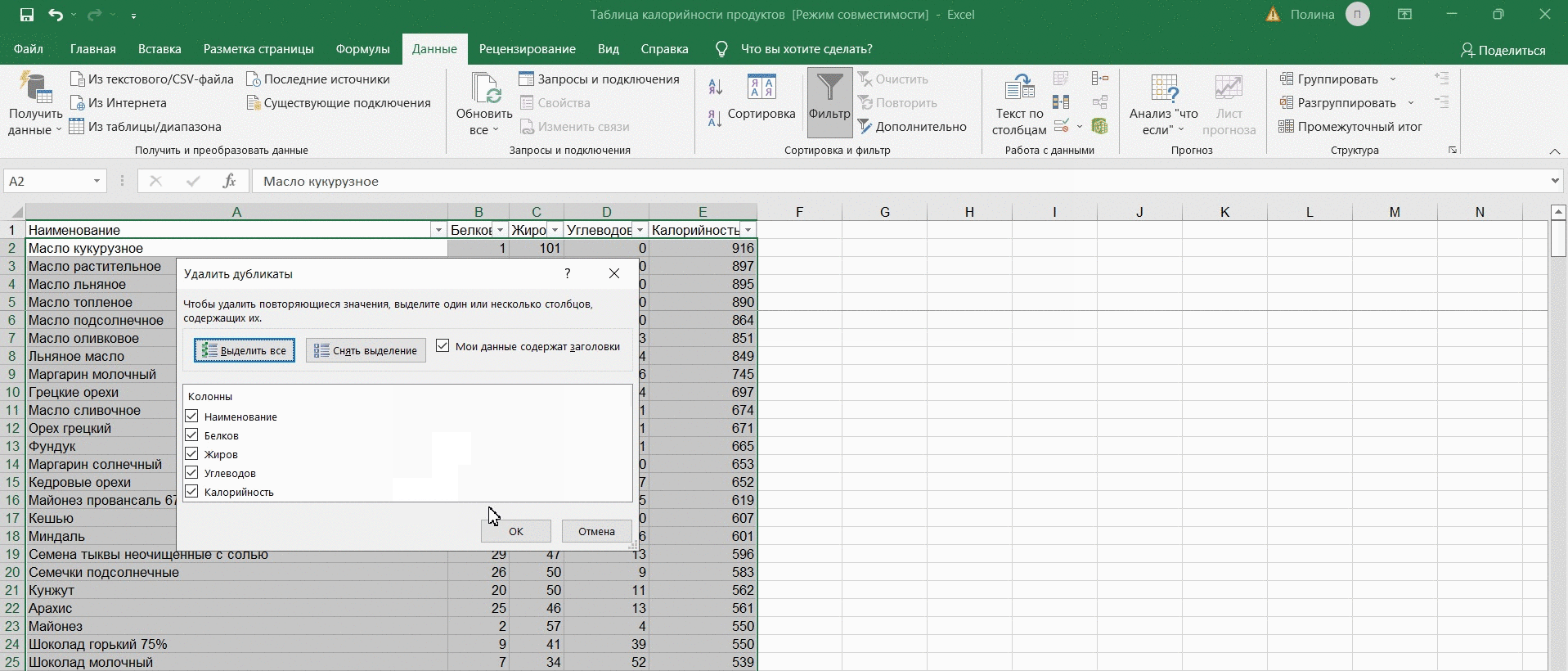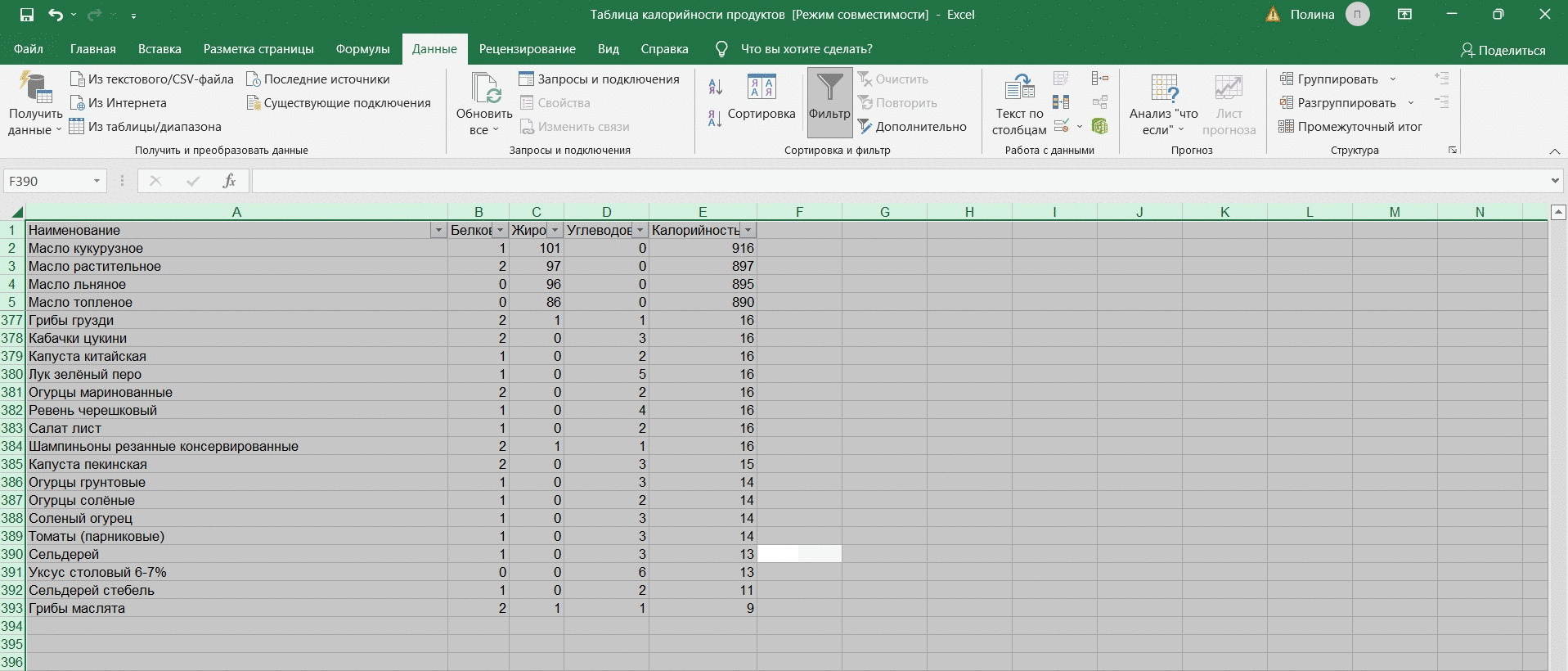
Шаг 5. Убираем дубли
При удалении повторяющихся данных важно сравнивать их сразу по нескольким признакам. Потому что если совпадает лишь один признак, то строка может повтором и не быть.
Идем в «Данные» — «Очистка данных» — «Удалить дубликаты». Важно, чтобы галочки стояли на всех столбцах. При таких настройках функция удалит строку как дубликат лишь при совпадении всех переменных, и вы не потеряете ничего нужного.
Напоследок
Предварительная обработка и очистка данных важны. Перепутанные данные на входе приводят к некорректным выводам.
Ваши выводы получатся верными, если вы:
- знаете источник данных,
- понимаете, как источник данные собирал и обрабатывал,
- понимаете, зачем вам эти данные и чем вы занимаетесь с ними,
- заранее выдвинули гипотезу и следите за точностью вычислений.
Подводя итоги:
Возможно, вам пригодится:

Как составить креативный контент-план

Как совместно работать в Google Документах

Как различать события, обещания и мнения
